
Ruby on Rails 6.0.3.1 and 5.2.4.3 have been released, and they include a patch for CVE-2020-8166, which we had reported via HackerOne.
The vulnerability is the “ability to forge per-form CSRF tokens given a global CSRF token”. What this means is that in hardened environments where each form is protected by its own unique CSRF token, an attacker can forge a valid per-form token if they have access to the global CSRF token.
This blog post will, for the sake of brevity and focus, assume an understanding of CSRF and why CSRF tokens are important. If you need some background, I suggest reading up with these OWASP and Portswigger articles.
Rails CSRF Tokens and Per-Form CSRF Tokens
Rails provides the global CSRF token for the user session in the <HEAD> of the HTML file.
<title>Blog</title> <meta name="csrf-param" content="authenticity_token" /> <meta name="csrf-token" content="hotX+T9rYuXWR5JNWc6A5MhMEGO8uv7H74KbvRz+WnL98caHe99MtGco8HsiyvUsE+bu1g6YMNCIuiq+0+56zQ==" />
The csrf-token is then submitted as the authenticity_token in all HTML form requests. In the default configuration, this is a global token. Consequently, if it were exposed CSRF attacks would be possible against any endpoint in the application.
To harden the environment, developers can enable per-form CSRF tokens. This means that each individual form requires its own CSRF token. This prevents exposure of a token on any given page from being used to execute a CSRF attack against something far more serious, such as changing a password.
The per-form CSRF token is created in request_forgery_protection.rb with the per_form_csrf_token() function.

The per_form_csrf_token() function takes session, action_path, and method parameters: method is the HTTP verb used in the request, action_path is the URL route in the action method in the <form>, and session is a special object Rails uses to track a user’s session. The function then calls csrf_token_hmac(), and passes the session object along with the action_path and method, the later two concatenated with a “#” and downcased. If the form looks like this
<form action="articles/edit/1" method="POST"> ...
then the value passed to csrf_token_hmac() might look like ”articles/edit/1#post”. However, in practice, Rails forms embed a hidden <input> tag into the forms with the method, and this is the value used for the method parameter. For editing, Rails prefers to use the PATCH method, and reserves POST for creating new content. So what is passed to csrf_token_hmac() is going to look like “articles/edit/1#patch”.
The csrf_token_hmac() function processes both the session and the “action_path#method” by constructing an HMAC of the “action_path#method” string, which is called identifier.

Here the identifier is the “action_path#method” string, and the session is used to generate the secret key for the HMAC using the function real_csrf_token().

The real csrf token is stored in the session like so: session[:_csrf_token]. If it is does not exist already, it is generated using a Secure Random function, and stored base64 encoded. As it is binary data, the token is then base64 decoded before returning to the calling function. When called by csrf_token_hmac(), that binary token is the secret key used in the HMAC to construct the per-form CSRF token.
The Vulnerability
Assuming we do not know the secret key for the HMAC construction, the per-form CSRF token looks secure. We know what values are hashed, but don’t know the secret. However, this is where the vulnerability lies. If you recall the global csrf-token that is included in the <head> of the page, this token leaks the value used as the key. We can see this is the masked_authenticity_token() function.
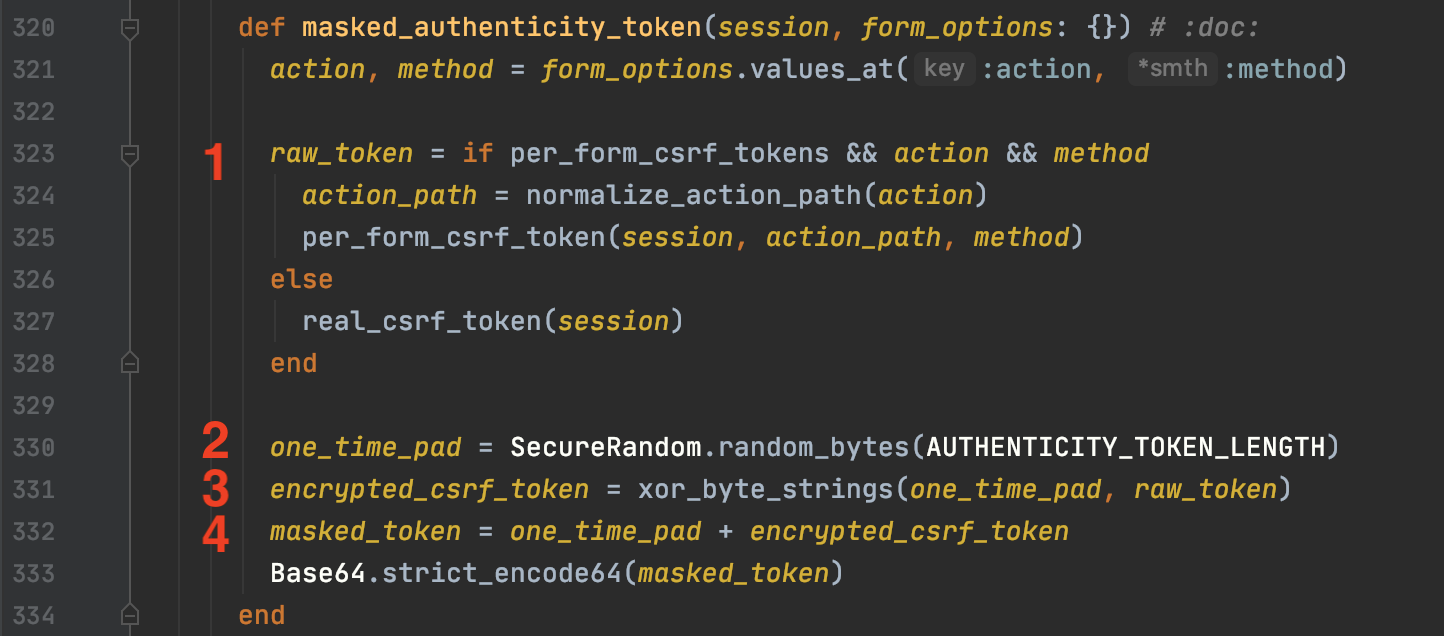
At (1) we see that the raw_token is populated either with the value of per_form_csrf_token(), or real_csrf_token(). If the code takes the real_csrf_token() route, then raw_token contains the secret stored in session[:_csrf_token]. For generating the global CSRF token, this was found to be the case, which is why our exploit was successful. Next, a one_time_pad is generated at (2) using a Secure random number generator. This one time pad is then XOR’d with the raw_token. One time pads are considered extremely secure. However, where the security completely falls apart is at (4), where the one time pad is prepended to the encrypted CSRF token and returned, base64 encoded. This is akin to encrypting sensitive secrets each with their own key, but providing the key along with the ciphertext.
To exploit this, we must simply do the following.
Get access to a global CSRF token, either through some sort client side code execution, or in the way we discovered the vulnerability, by initially finding the global token exposed in a URL
Base64 decode the token
Split the token in half, separating the one time pad from the masked token
XOR the two together, thereby unmasking the token
Identify an endpoint that is protected by per-form CSRF tokens. Lets say that endpoint sits at “/articles/2”, and we know that the method used is “patch”
Forge the per-form token by creating an HMAC using SHA-256 where the secret key is the unmasked token, the hashed value is “/articles/2#patch” and take the digest, but not the Hex digest of the hash. We want the binary and not a hexadecimal string
We know that Rails will attempt to unmask our forgery, so we need to provide our own one time pad that will not corrupt our forgery. The answer to this is simple, since anything XOR’d with zero (0) is itself. So we prepend our forgery with nulls of the correct length.
Finally prepare the encoding. First base64 the null one time pad and forgery, then URL-encode that.
This can then be used in a CSRF attack as the authenticity_token for a form updating “/articles/2”
The Patch
Since the vulnerability lies in the real_csrf_token() exposing the secret CSRF token through the masked_authenticity_token() function, the fix that was implemented in Rails 6.0.3.1 and 5.2.4.3 protects that token with another HMAC construction. In the patch for masked_authenticity_token() we see:

real_csrf_token() has been replaced by global_csrf_token(). What this new function does is nearly identical to the per-form CSRF token generation, except the value to be hashed is a known constant.

Hashing a known constant is fine because the hashed value was never the issue. It is the key that is used to create the HMAC that is now kept secret. real_csrf_token() exposed the secret, but global_csrf_token() now returns an HMAC that uses the secret, but does not reveal it. The server can now verify the validity of the global CSRF token without exposing the secret key to the browser.
Timeline
8 November 2019 - Disclosed to Hackerone
25 Novermber 2019 - Vulnerability verified
18 May 2020 - Patch released/Bounty awarded

